CDO AI Forum – Chicago – Westin Chicago River North – June 22, 2026 Join top AI and Data leaders in Chicago to explore the strategies, governance, and innovations driving enterprise performance. Connect, learn, and gain actionable insights — reserve your seat today.
The State of AI Reliability: Why Trust Is Becoming the Biggest Barrier to Scaling AI AI adoption is accelerating across the enterprise, but reliability is lagging. In a new research report, The State of AI Reliability: Perspectives from Data & AI Leaders, CDO Magazine, in partnership...
CDO Magazine Announces the Top 30 Healthcare Innovators 2026 Across healthcare, AI has moved from experimentation to enterprise execution. CDO Magazine recognizes the Top 30 Healthcare Innovators 2026 who are turning that shift into measurable impact. This year...
Branded Content
Enterprise Unstructured Data can Solve the Context Challenge for AI. Flexor is Leading the Way
Written by: CDO Magazine
Updated 10:43 AM EST, March 2, 2026

Enterprise AI investment reached unprecedented levels in 2025, with global spending projected to exceed $337 billion according to research from SAP and Verdantix. Yet for many enterprises, these investments have not translated into better decisions or measurable business outcomes.
Despite this surge in spending, a troubling pattern persists: according to MIT research, only 5% of AI pilot programs achieve rapid revenue acceleration, with the vast majority stalling and delivering little to no measurable impact on the bottom line.
In conversations with data leaders across industries, a consistent bottleneck emerges. While challenges range from model selection to infrastructure complexity, the core issue revolves around data. Specifically, the 80% of enterprise information that exists as unstructured data, and remains inaccessible, inconsistent, or unreliable for decision-making at scale.
Unstructured data encompasses the PDFs, emails, contracts, chat logs, support tickets, CRM notes, call transcripts and internal communications that capture the reality of business operations. This isn’t supplementary information. It represents the majority of what enterprises know about their customers, operations, and market dynamics. Today, this data is central to enterprise AI and decision-making, but it is still handled in ways that make it unreliable. Many organizations push raw, uncontextualized information directly into AI models and pipelines, then wonder why results disappoint.
The issue is not a lack of intelligence in AI models, but the absence of a trusted, decision-ready data foundation.
The consequences show up in everyday decisions. A customer service agent relies on an AI assistant and provides outdated policy information. A compliance team misses a regulatory change buried in email threads. A leadership dashboard surfaces conflicting insights depending on which system is queried.
The result isn’t just poor output quality, it’s lost confidence. Leaders stop trusting dashboards, frontline teams stop relying on AI systems, and organizations revert to intuition instead of evidence.
This shift toward data preparation and contextualization has given rise to a new class of enterprise data architecture. One company pioneering and operationalizing this approach is Flexor, helping enterprises turn unstructured data into a trusted foundation for consistent decision-making. Flexor was first recognized by CDO Magazine in August 2024 as a “Product to Watch.”
From Innovation to Industry Standard
What sets companies like Flexor apart from the dozens of vendors claiming to solve the unstructured data challenge? The answer lies not just in technical capabilities, but in a fundamental understanding of how AI systems and unstructured data must interact.
“Most enterprises assume their AI struggles stem from model limitations,” explains Or Zabludowski, CEO of Flexor. “But competitive AI advantages come from capturing the nuances of your specific business – information that remains locked in proprietary unstructured data. The question isn’t whether your model is sophisticated enough. It’s whether your data is ready for any model to use effectively.”
This philosophy shapes every aspect of Flexor’s platform, which serves as a decision-grade foundation for unstructured enterprise data across its full lifecycle: extraction and unification of diverse sources, cleaning and deduplication, normalization across formats, enrichment, and added context (both data-specific and organizational). The output isn’t just “processed” data – it’s context-ready information structured for immediate use by humans, AI agents and applications, and agentic workflows.
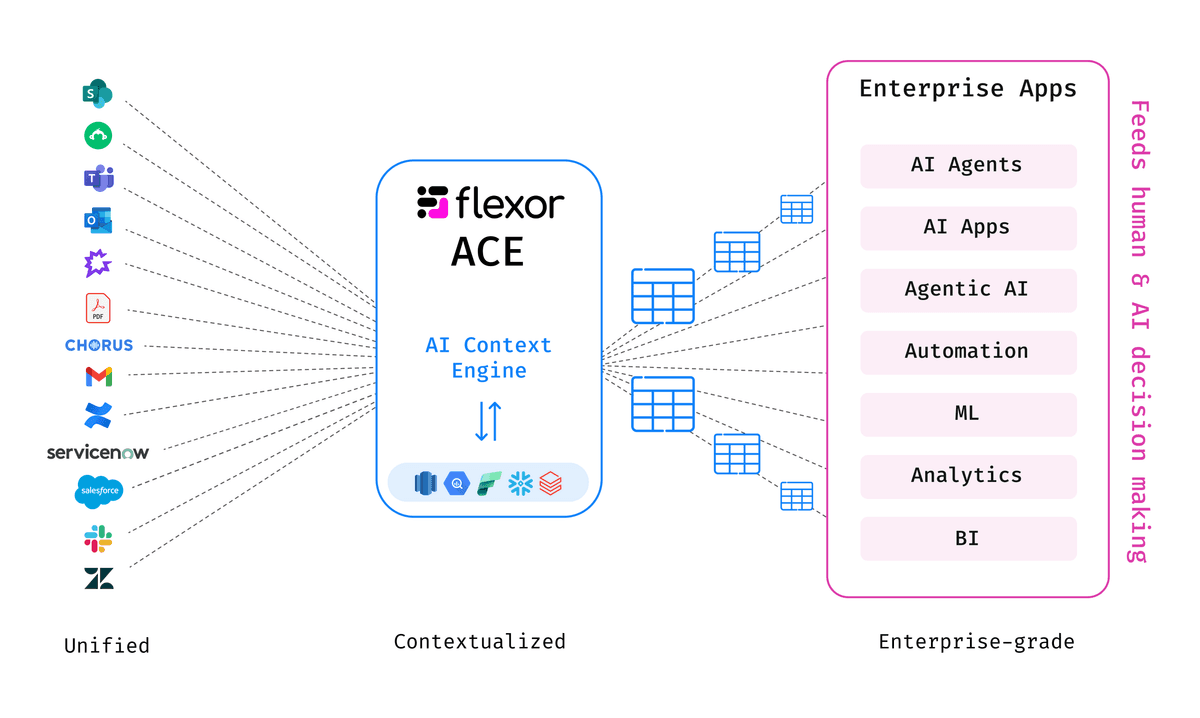
The company’s momentum validates this approach across a broad range of industries and operational use cases. Enterprises in sectors such as e-commerce, financial services, logistics, education, and automotive are using Flexor to operationalize unstructured data for functions including customer experience optimization, risk and compliance workflows, predictive analytics, and enterprise AI knowledge systems.
Flexor was recently recognized with the CDAO Innovation Award, reflecting growing industry validation of this approach.
The Benchmark Framework: Three Operational Pillars
As enterprises move from AI experimentation to production, a clear operating model for handling unstructured data is emerging. Flexor’s deployments reveal three operational pillars that consistently separate scalable AI from stalled pilots.
-
Continuous Learning Through Feedback Loops
One persistent challenge facing enterprise AI is the black box problem. Data teams deploy models but lack visibility into what happens after a user query. Did the agent provide outdated information? Are unsupported workflows being triggered? Are compliance risks emerging without detection?
These blind spots create major inefficiencies and lost revenue opportunities, making it nearly impossible to confidently move from proof-of-concept to production deployment.
Flexor addresses this by creating closed feedback loops around unstructured data. The platform captures model interactions and system outputs, feeding this information back into the underlying datasets. This creates continuously improving systems where models become smarter over time, and data teams gain visibility into what’s working and what requires attention.
Critically, this intelligence is accessible to more than just data scientists. Because Flexor outputs SQL-ready structured data, insights and improvements can be delivered directly to business teams through familiar dashboards, reports, and operational workflows.
These feedback loops transform unstructured data from a static asset into a continuously improving decision system.
-
Context-Aware Data Structuring
Context isn’t optional when working with unstructured data. It’s a make-or-break for enterprises looking to achieve success with GenAI.
Consider a common scenario: An AI system needs to answer a question about current savings account promotions. The available data sources include three files named “Savers_promos_2025.pdf,” “Savers_promos_final.pdf,” and “Savers_promos_updated.pdf.” Without contextual understanding, even a human would struggle to identify the most current, relevant information. The AI model attempting the same task isn’t at fault – it’s the data architecture that failed to provide necessary context.
Flexor structures data to eliminate this ambiguity. The platform organizes information into distinct knowledge layers:
- Formal knowledge: Current policies, updated product documentation, active guidelines
- Tacit knowledge: Insights embedded in customer service interactions and internal communications
- Archived knowledge: Outdated policies and documents, clearly marked as historical
With this contextual organization, AI models can easily distinguish relevant from irrelevant information. More importantly, they become domain-specific and business-specific, speaking the organization’s language rather than providing generic responses.
In regulated or customer-facing environments, this ambiguity can lead not just to bad answers, but to compliance exposure, financial loss, and reputational damage.
“Context isn’t a nice-to-have – it’s the difference between confident decisions and systemic risk,” notes Zabludowski. “We built Flexor to make context the default, not an afterthought that requires custom engineering for every deployment.”
-
Enterprise-Grade Integration and Governance
Technical elegance means little if deployment requires replacing existing data infrastructure. Enterprises won’t abandon proven data warehouses, vector databases, and analytics platforms for a new tool, regardless of its capabilities.
Flexor integrates seamlessly with existing data stacks, functioning as a purpose-built layer that enhances rather than replaces current infrastructure. The platform provides end-to-end support for GDPR, HIPAA, and SOC 2 compliance, with governance controls built into the architecture rather than bolted on afterward.
This integration-first approach delivers two critical benefits. First, onboarding happens quickly without workflow disruption – implementations that would traditionally require months of custom development can be completed in weeks. Second, all data flowing through the system is standardized, eliminating discrepancies that occur when different AI agents or applications interpret the same underlying information differently.
The SQL accessibility further democratizes unstructured data, allowing business analysts and operations teams to work with previously inaccessible information using familiar tools and query languages.
Proof in Production: Results Across Industries
Organizations across sectors are operationalizing unstructured data through Flexor with measurable results. Two examples demonstrate the breadth of impact:
E-commerce: In large-scale e-commerce environments, unstructured data from product reviews, customer support tickets, return requests, and service conversations contains the most accurate signals of customer intent and operational friction. Yet without structure and context, this information remains fragmented and underutilized.
A major online retailer used Flexor to unify and structure these interactions into a single, contextual data foundation. By making customer narratives decision-ready and accessible across analytics and operational workflows, the organization achieved a 40% improvement in response times, a 25% reduction through better issue identification, and a 15% increase in upsells driven by more relevant product recommendations during service interactions.
“Flexor has revolutionized our approach to handling refunds and customer satisfaction,” explains the retailer’s Data Director. “By simplifying our data preparation process, we’ve saved costs and improved our customer satisfaction. It’s transformed how we balance customer-friendliness with business sustainability.”
Financial Services: In financial services, fragmented customer communication data creates blind spots that directly impact trust, compliance, and lifetime value. Critical insights are often buried across chat logs, emails, call transcripts, and internal notes, making it difficult to deliver consistent, personalized experiences while maintaining regulatory confidence.
A leading bank leveraged Flexor to structure and unify unstructured customer interactions into a single, governed view of customer intelligence. This decision-ready foundation enabled proactive, context-aware engagement across channels, resulting in a 15% increase in customer lifetime value while maintaining strict governance and auditability requirements.
By transforming unstructured conversations into trusted, contextual data, the organization moved from reactive service to proactive relationship management, without rebuilding existing data infrastructure or introducing additional compliance risk.
The Blueprint for Enterprise AI’s Next Decade
As enterprises move deeper into 2026, unstructured data management is transitioning from competitive advantage to operational necessity. The market has moved past exploration and into operationalization, and the organizations succeeding at scale are those that solved the data foundation challenge first.
The numbers tell the story: over 80% of AI projects fail – twice the rate of traditional IT projects – according to RAND Corporation, with data quality and readiness cited as the top obstacle by 43% of enterprise data leaders in Informatica’s 2025 CDO Insights survey. Organizations that operationalize unstructured data now position themselves to lead in an increasingly AI-driven business landscape. Those that continue to struggle with data foundations will find their AI investments delivering diminishing returns.
Flexor’s roadmap reflects this evolution, with planned expansions in real-time data freshness capabilities, deeper governance controls for regulated industries, and broader integration options for emerging AI architectures including agentic systems and advanced retrieval-augmented generation implementations.
“We’re seeing a fundamental shift in how enterprises think about data architecture,” observes Zabludowski. “Two years ago, conversations focused on whether to invest in unstructured data capabilities. Today, the conversation is about how to operationalize them effectively. That’s the inflection point we’ve been anticipating.”
From CDO Magazine’s perspective, Flexor’s framework represents more than a solution to today’s challenges – it’s the blueprint for how enterprises will need to handle data in the AI era. As the market continues to mature, the principles Flexor has operationalized – continuous learning, contextual awareness, and seamless integration – will become the standard by which other unstructured data platforms are measured.
The question for data leaders isn’t whether unstructured data management will become table stakes. It’s whether their organizations are building the right foundation now, or locking in another generation of AI disappointment while competitors move ahead.
The views and opinions expressed in this article are solely those of Flexor’s and do not reflect the views, positions, or policies of CDO Magazine.



